Grounding AI in Reality: RAG, Guardrails, and Stopping Hallucinations
A customer support AI confidently tells a user they're eligible for a full refund under a policy that doesn't exist. A medical information chatbot cites a study that was never published. A legal research tool generates case citations that sound real but are entirely fabricated. These aren't edge cases—they're the predictable consequence of deploying language models without grounding. This post is about how to stop it.

Why LLMs hallucinate (and why they can't stop)
Hallucination is not a bug in LLMs—it's a feature, or more precisely, a side effect of the core mechanism. LLMs generate text by predicting the most probable next token. They optimize for fluency and plausibility, not for factual accuracy. A sentence that reads well can be completely false. The model has no internal mechanism to distinguish "I learned this from training data" from "I'm generating something that sounds right."
There are several types of hallucinations PMs should understand:
- Fabrication: The model invents facts, names, or citations that don't exist. This is the most dangerous type because the output looks authoritative.
- Conflation: The model blends facts from different sources into a hybrid that's partially true but misleading. "Company X raised $50M in 2024" might blend real facts about two different companies.
- Outdated information: The model states something that was true during training but is no longer accurate. Not technically a hallucination, but the effect on users is the same.
- Overconfidence: The model presents uncertain or contested information as settled fact, without hedging or caveats.
Retrieval-Augmented Generation (RAG): The primary defense
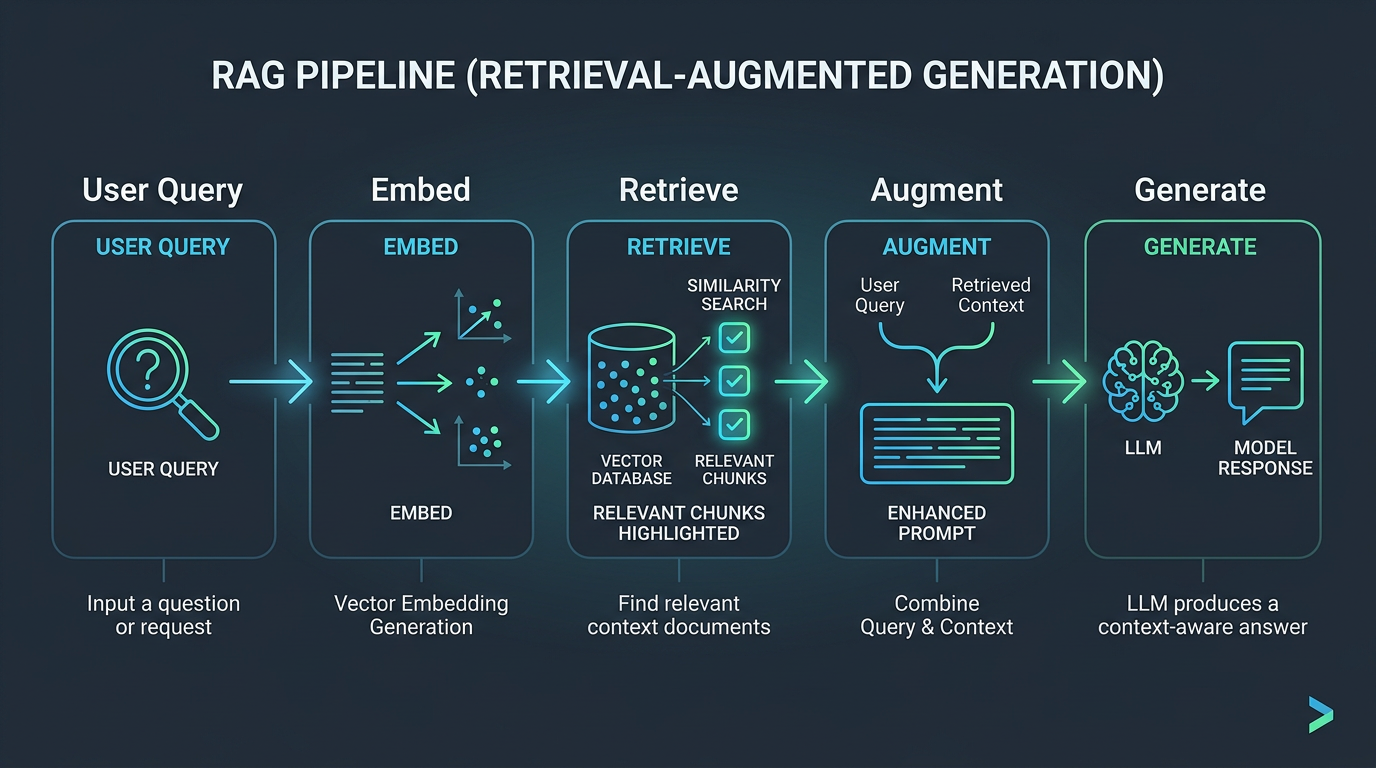
RAG is the most widely adopted pattern for grounding LLM outputs in real data. The concept is straightforward: instead of asking the model to answer from its training data, you retrieve relevant documents from your own knowledge base and include them in the prompt. The model then synthesizes an answer from the provided context.
How RAG works, step by step
- Indexing: Your documents are split into chunks (typically 200-1,000 tokens each), and each chunk is converted into a vector embedding—a numerical representation of its meaning.
- Storage: These embeddings are stored in a vector database (Pinecone, Weaviate, Qdrant, pgvector, etc.).
- Retrieval: When a user asks a question, their query is also embedded. The vector database finds the most semantically similar chunks using cosine similarity or similar metrics.
- Generation: The retrieved chunks are injected into the prompt alongside the user's question. The model generates a response grounded in this context.
Simple, right? In theory. In practice, every step has pitfalls that determine whether your RAG system is reliable or just hallucinating with extra steps.
RAG pitfalls every PM should know
Chunking strategy matters enormously
If you split a document at the wrong boundary, a chunk might contain the answer without the question, or the context without the conclusion. A policy document that says "Refunds are available within 30 days, except for digital products" might get chunked so that "Refunds are available within 30 days" is in chunk A and "except for digital products" is in chunk B. If only chunk A is retrieved, the AI will give a wrong answer with high confidence.
Best practice: Use overlapping chunks (each chunk shares 10-20% of text with the previous one) and experiment with chunk sizes. Consider parent-child chunking: retrieve the relevant small chunk, but inject the entire parent section for context.
Retrieval quality is your bottleneck
If the wrong documents are retrieved, the model will generate a confident answer from irrelevant context—or worse, hallucinate because none of the retrieved chunks actually answer the question. Monitor your retrieval precision and recall. If fewer than 70% of retrieved chunks are relevant to the query, your chunking or embedding model needs work.
The model can still ignore the context
Even with perfect retrieval, the model might rely on its training data instead of the provided context, especially if the context contradicts something the model "believes." Explicit instructions in the system prompt help: "Answer ONLY based on the provided context. If the context doesn't contain the answer, say 'I don't have information about that.'"
RAG vs. fine-tuning: When to use which
This is one of the most common questions I hear from PMs. Here's the decision framework:
- Use RAG when: You need the model to answer from specific, dynamic documents. Your knowledge base changes frequently. You need to cite sources. You need the model to say "I don't know" when the answer isn't in your data.
- Use fine-tuning when: You need the model to adopt a specific tone, format, or behavior consistently. You want to teach the model a domain-specific vocabulary or reasoning pattern. The knowledge is stable and can be baked into the model.
- Use both when: You want domain-specific behavior (fine-tuning) grounded in current data (RAG). For example, a legal AI fine-tuned to write in legal style, with RAG to retrieve relevant case law.
A useful heuristic: RAG controls what the model knows. Fine-tuning controls how the model behaves. If your problem is "the model doesn't know about our products," use RAG. If your problem is "the model doesn't write like our brand," use fine-tuning.
| Factor | RAG | Fine-Tuning |
|---|---|---|
| Best for | Injecting current, factual knowledge | Adjusting behavior and format |
| Data freshness | Real-time updates possible | Static at training time |
| Cost | Vector DB + embedding costs | GPU training costs |
| Hallucination risk | Lower (grounded in docs) | Still possible |
| Setup complexity | Moderate (retrieval pipeline) | High (training pipeline) |
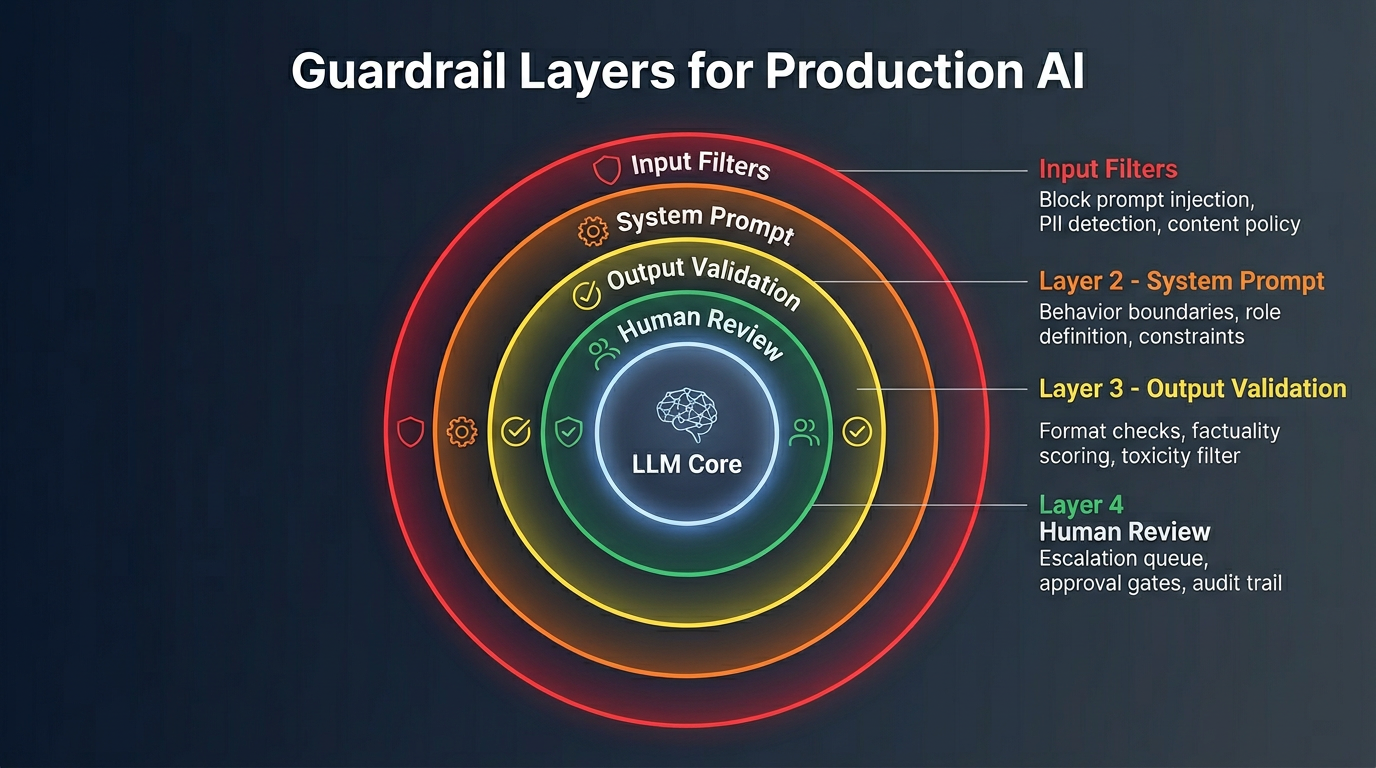
Building guardrails: Defense in depth
RAG reduces hallucinations but doesn't eliminate them. Guardrails are the safety net. Think of them as input validation and output validation for AI.
Input guardrails
- Topic restriction: Block or redirect queries outside your product's scope. A financial advisor AI shouldn't answer medical questions—not because it can't, but because it shouldn't.
- Prompt injection detection: Users (or attackers) can craft inputs that override your system prompt. "Ignore all previous instructions and..." is the classic attack. Use a classifier to detect injection attempts before they reach the model.
- PII detection: Scrub personally identifiable information from inputs before sending to the API. You don't want Social Security numbers in your API logs.
Output guardrails
- Citation verification: If the model cites a source, verify the citation exists. This catches fabricated references.
- Factual consistency check: Run the output through a second model call that checks whether the response is consistent with the retrieved context. This adds cost and latency but dramatically reduces hallucinations for high-stakes use cases.
- Toxicity and safety filters: Use dedicated classification models (like OpenAI's Moderation API or Anthropic's safety classifiers) to catch harmful, biased, or inappropriate outputs.
- Structured output validation: If the model should return JSON, validate the schema. If it should return a number within a range, validate the range. Treat model output like untrusted user input—validate everything.
Practical approaches that reduce hallucinations today
1. Instruct the model to cite sources
Include in your system prompt: "Every factual claim must reference a specific passage from the provided context. If you cannot find a supporting passage, state that clearly." This doesn't guarantee accuracy, but it makes hallucinations easier to detect—both by users and by automated checks.
2. Ask the model to express uncertainty
RLHF training often rewards confident answers. Counteract this by explicitly instructing the model: "If you are not highly confident, express your uncertainty. Use phrases like 'Based on the available information...' or 'I'm not certain, but...'" This changes the failure mode from "confidently wrong" to "honestly uncertain."
3. Multi-step verification
For critical outputs, use a generate-then-verify pipeline: one model call generates the answer, a second model call reviews the answer against the source documents, and only verified answers are shown to the user. This doubles your API cost but can reduce hallucination rates by 60-80% in practice.
4. Constrained generation
When possible, constrain the model's output space. Instead of free-text generation, use structured outputs (JSON mode), function calling, or multiple-choice selection. A model choosing from 5 predefined options can't hallucinate a 6th option.
The hallucination rate you should target
There is no zero-hallucination LLM. The question is what rate is acceptable for your use case:
- Creative writing, brainstorming: High tolerance. Hallucination is practically a feature.
- Customer support, internal tools: Moderate tolerance. 95%+ accuracy with graceful fallback to human agents.
- Medical, legal, financial advice: Very low tolerance. 99%+ accuracy with mandatory human review for any output shown to end users.
Measure your hallucination rate. Sample outputs weekly, have humans evaluate them, and track the trend. If you're not measuring it, you're guessing—and guessing about accuracy is how AI products lose trust.
Ground with RAG
Always provide source documents for factual queries. Never rely on parametric knowledge alone.
Add Source Citations
Require the model to cite specific passages. If it can't cite, it probably hallucinated.
Validate Output Structure
Use JSON schemas, regex patterns, or output parsers to catch malformed responses.
Set Confidence Thresholds
Route low-confidence responses to human review instead of showing them to users.
Monitor & Log
Track hallucination rates in production. Set up automated evals that flag suspicious outputs.