The Cost of Intelligence: Understanding LLM Pricing, Tokens, and Latency Tradeoffs
I've watched three AI startups in the last year discover the same thing: their demo is magical, their Series A is funded, and their unit economics are catastrophic. The model that makes the demo sing costs $0.15 per interaction. At 50,000 daily active users making 10 requests each, that's $75,000/month in API costs alone—before you've paid a single engineer. This post is about how to think about LLM costs like a PM, not a researcher.

How LLM pricing actually works
Every major LLM provider uses token-based pricing with a critical split: input tokens (what you send) and output tokens (what the model generates) are priced differently. Output tokens are almost always more expensive because generation is computationally harder than processing.
Here's a snapshot of the pricing landscape in early 2026:
- GPT-4o: $2.50/1M input tokens, $10.00/1M output tokens
- GPT-4o-mini: $0.15/1M input, $0.60/1M output
- Claude 3.5 Sonnet: $3.00/1M input, $15.00/1M output
- Claude 3.5 Haiku: $0.80/1M input, $4.00/1M output
- Gemini 1.5 Pro: $1.25/1M input, $5.00/1M output
- Open-source (Llama 3, Mixtral, self-hosted): GPU cost only, no per-token fee—but you're paying for infrastructure.
The spread between the cheapest and most expensive option is roughly 100x. GPT-4o-mini costs $0.15/1M input tokens; Claude 3.5 Sonnet costs $3.00/1M. For the same workload, one is 20x more expensive than the other. This isn't a rounding error—it's the difference between a profitable product and a money pit.
| Model | Input/1M tokens | Output/1M tokens | Latency (TTFT) | Best For |
|---|---|---|---|---|
| GPT-4o | $2.50 | $10.00 | ~300ms | Complex reasoning |
| GPT-4o-mini | $0.15 | $0.60 | ~150ms | Simple tasks, high volume |
| Claude 3.5 Sonnet | $3.00 | $15.00 | ~350ms | Long context, analysis |
| Gemini 1.5 Flash | $0.075 | $0.30 | ~100ms | Speed-critical, multimodal |
| Llama 3.1 70B | Self-hosted | Self-hosted | Varies | Data privacy, control |
The unit economics exercise every PM should do
Before you ship any AI feature, do this napkin math:
- Average input tokens per request: System prompt + context + user message. Measure this from your prototype.
- Average output tokens per request: How long are typical responses? 200 tokens for a short answer, 1,000+ for a detailed response.
- Requests per user per day: How chatty is the usage pattern?
- Daily active users (DAU): Current + projected.
Here's a worked example: a customer support AI assistant.
- System prompt: 800 tokens
- RAG context: 2,000 tokens
- Conversation history: 3,000 tokens
- User message: 200 tokens
- Total input: ~6,000 tokens
- Average output: ~500 tokens
- Cost per request (GPT-4o): (6,000 × $2.50 + 500 × $10.00) / 1,000,000 = $0.02
- Cost per request (GPT-4o-mini): (6,000 × $0.15 + 500 × $0.60) / 1,000,000 = $0.0012
At 10,000 DAU × 5 requests/day = 50,000 daily requests:
- GPT-4o: $1,000/day → $30,000/month
- GPT-4o-mini: $60/day → $1,800/month
Same feature. Same user experience (mostly). 16x cost difference.
Bigger isn't always better: The model selection framework
The instinct is to use the "best" model—GPT-4o, Claude 3.5 Sonnet—for everything. This is like using a Ferrari to get groceries. It works, but it's absurdly inefficient.
Here's a framework for model selection:
Tier 1: Classification, extraction, and simple tasks
Intent classification, entity extraction, sentiment analysis, simple formatting. These tasks don't need frontier models. GPT-4o-mini or Claude Haiku handle them with 95%+ accuracy at a fraction of the cost. If you're routing customer support tickets to the right department, you don't need GPT-4o.
Tier 2: Generation with grounding
Answering questions from retrieved context, summarizing documents, generating responses based on templates. Mid-tier models work well here because the retrieved context does the heavy lifting. The model's job is synthesis, not deep reasoning.
Tier 3: Complex reasoning and generation
Multi-step reasoning, creative writing, code generation, nuanced analysis. This is where frontier models earn their premium. But even here, ask: does every request need Tier 3? Or can you route only the complex ones?
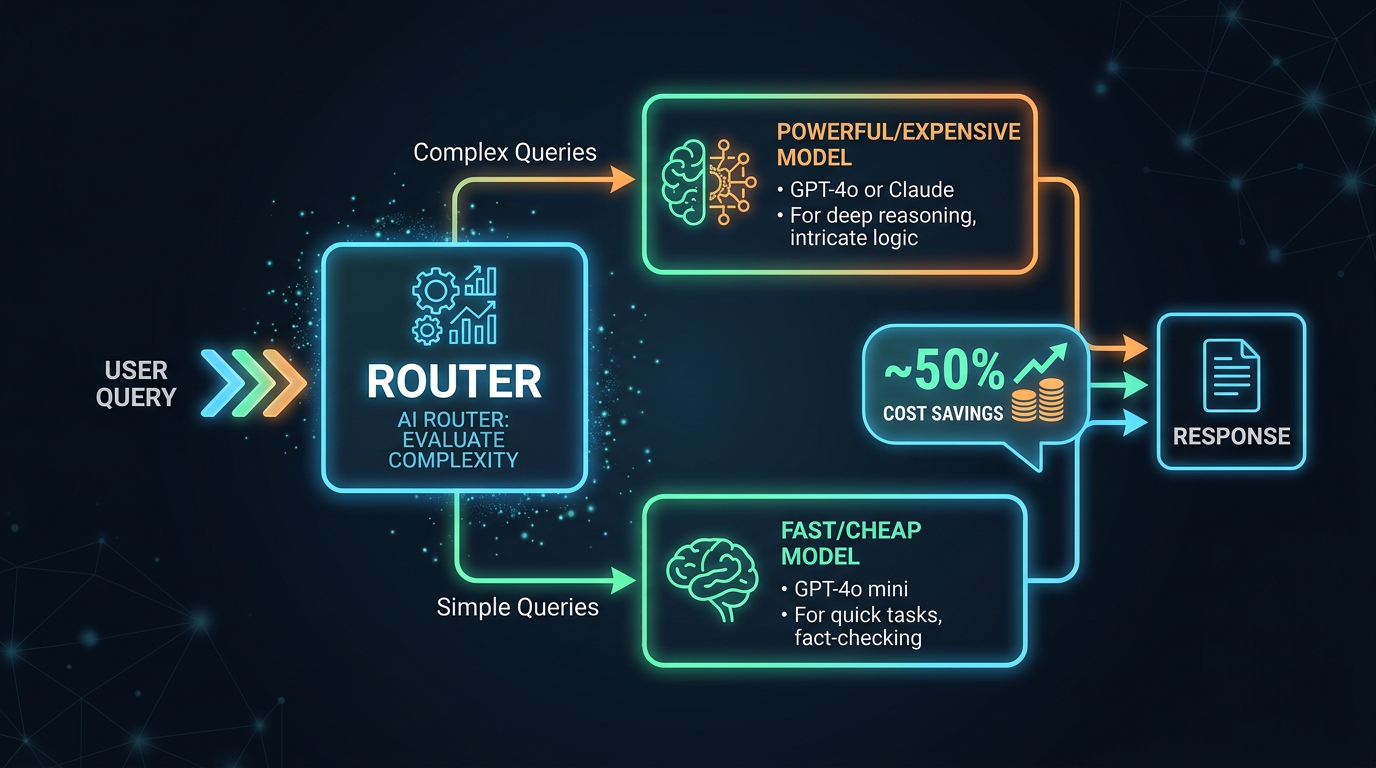
Model routing: The architecture of cost optimization
The most sophisticated AI products don't use a single model. They use model routing—a lightweight classifier that examines each request and routes it to the appropriate model tier.
If 70% of your requests are Tier 1, 20% are Tier 2, and 10% are Tier 3, model routing can reduce your blended cost by 60-80% compared to using a Tier 3 model for everything.
The router itself can be a small, fast model (or even a rule-based classifier). The key insight is that the router doesn't need to be perfect—it needs to be right enough that the cost savings outweigh the occasional quality drop from routing a complex query to a simpler model.
Latency: The other cost nobody budgets for
Token-based pricing captures the financial cost. But there's another cost that directly impacts user experience: latency.
LLM latency has two components:
- Time to First Token (TTFT): How long before the first token appears. This is dominated by prompt processing time and is roughly proportional to input length.
- Tokens per second (TPS): How fast the model generates output. Larger models are slower. GPT-4o might generate at 60-80 tokens/second; GPT-4o-mini at 100-150 tokens/second.
For a response of 500 tokens:
- GPT-4o: ~0.5s TTFT + 500/70 ≈ 7.6s total
- GPT-4o-mini: ~0.2s TTFT + 500/120 ≈ 4.4s total
Three seconds doesn't sound like much, but in UX terms, it's the difference between "snappy" and "slow." Streaming mitigates this—users start reading immediately—but the total wait time still matters for perceived quality.
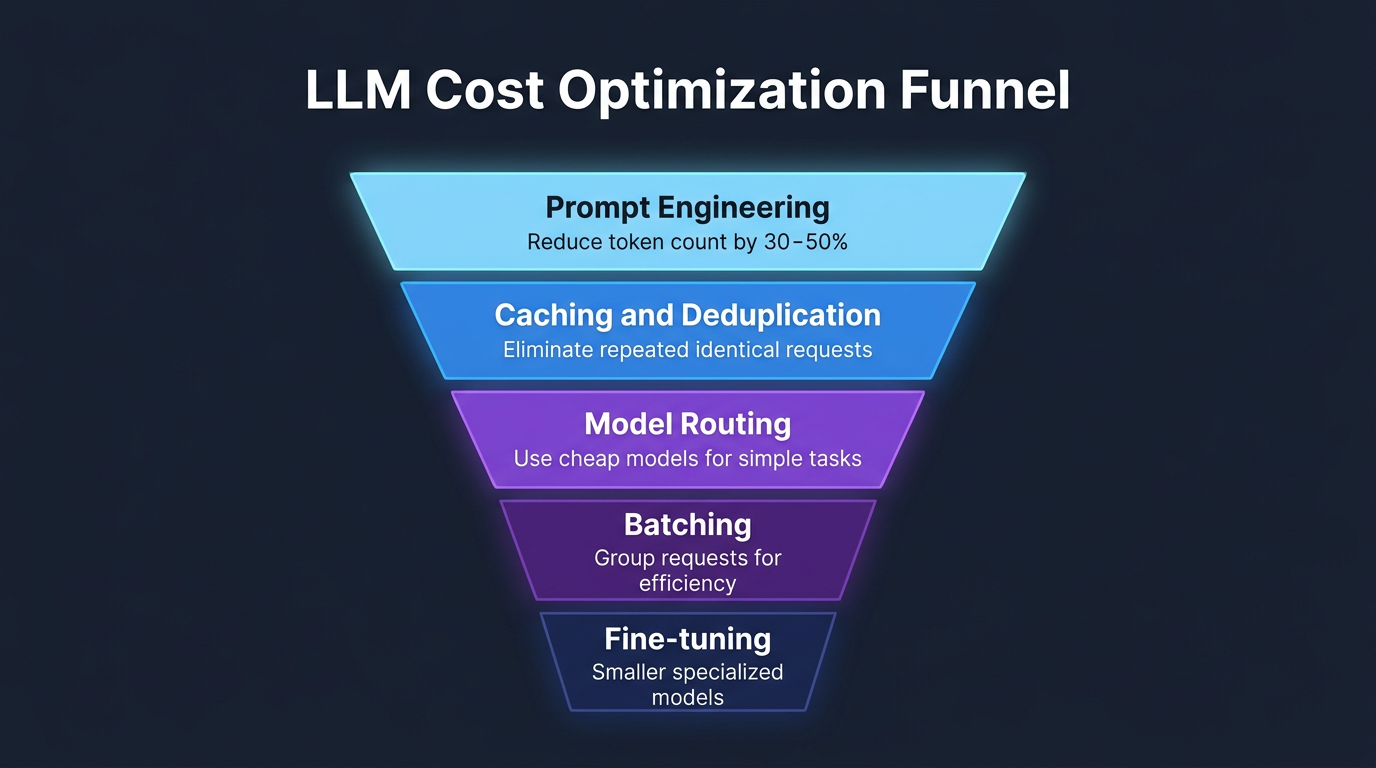
Strategies to reduce cost without reducing quality
1. Prompt optimization
Shorter prompts cost less. Audit your system prompts ruthlessly. That 2,000-token system prompt with 15 "do not" rules can probably be compressed to 800 tokens without losing effectiveness. Every token you remove is removed from every single API call.
2. Caching
If 30% of your queries are variations of the same 100 questions, cache the responses. Semantic caching (matching queries by meaning, not exact text) can dramatically reduce API calls. OpenAI and Anthropic both offer prompt caching features that reduce costs for repeated prompt prefixes.
3. Output length limits
Set max_tokens appropriately. If your use case needs 200-word responses, don't let the model generate 2,000 words. You're paying for every output token, and longer responses also mean higher latency.
4. Batch processing
If latency isn't critical (background processing, nightly reports), use batch APIs. OpenAI's batch API offers 50% discounts for asynchronous processing. Anthropic offers similar tiers.
5. Self-hosting open-source models
For high-volume, predictable workloads, self-hosting Llama 3.1 70B or Mixtral on your own GPUs can be dramatically cheaper than API pricing. The crossover point depends on volume—typically above 10-50M tokens/day, self-hosting starts winning. But you're now in the infrastructure business, with all the operational complexity that entails.
The pricing trajectory: Where is this going?
LLM pricing has dropped roughly 10x every 18 months. GPT-4 launched at $30/1M input tokens in 2023. GPT-4o in 2024 was $5/1M. GPT-4o in early 2026 is $2.50/1M. The trend is clear, but don't plan your business model around future price drops. Optimize for today's costs and treat future decreases as margin expansion.
The more interesting trend is the gap between frontier and commodity models is shrinking. Today's GPT-4o-mini performs at roughly the level of GPT-4 from two years ago, at 1/100th the cost. This means the model routing strategy gets better over time—the "cheap" tier gets more capable while staying cheap.
The PM's cost optimization checklist
- Calculate cost per request, per user, per month before launch
- Measure actual token usage (input + output) from your prototype
- Evaluate whether a smaller model achieves acceptable quality
- Implement model routing if you have heterogeneous query complexity
- Cache repeated queries and common prompt prefixes
- Set max_tokens limits appropriate to your use case
- Monitor cost per user weekly and set alerts for anomalies
- Use batch APIs for non-latency-sensitive workloads
- Build a cost dashboard visible to the product team, not just engineering