How LLMs Actually Work: A Product Manager's Mental Model
You are shipping an AI feature next quarter. Your engineers are debating fine-tuning vs. RAG, your designer wants to know why the model "hallucinates," and your CEO just asked why you can't "just use GPT-4 for everything." You need a mental model—not a PhD. This post is that mental model.

Start with the simplest truth: LLMs are autocomplete
Strip away the hype and a Large Language Model is a statistical next-token predictor. Given a sequence of tokens (words, sub-words, punctuation), the model outputs a probability distribution over the entire vocabulary for what comes next. It picks a token, appends it to the sequence, and repeats. That's it. The entire magic of ChatGPT, Claude, and Gemini is very sophisticated autocomplete.
Why does this matter for you as a PM? Because it sets the ceiling on what these models can do. They are not databases. They do not "know" your company's Q3 revenue. They have learned statistical patterns from massive text corpora, and they're interpolating from those patterns. When you understand this, hallucinations stop being surprising bugs and start being predictable behavior you can design around.
Tokens: The currency of LLMs
Models don't process words—they process tokens. A token is roughly ¾ of a word in English. "Unbelievable" might be three tokens: "un," "believ," "able." This matters for two reasons:
- Cost: You pay per token (input + output). A 2,000-word prompt is ~2,700 tokens. At $2.50/million input tokens (GPT-4o pricing), that's about $0.007 per request. Multiply by 100,000 daily users and the costs add up fast.
- Context window: Every model has a maximum number of tokens it can "see" at once. GPT-4o handles 128K tokens. Claude 3.5 handles 200K. But just because the window exists doesn't mean performance is uniform across it—more on that later.
As a PM, you should be able to estimate the token cost of any feature. Ask your engineers: "What's the average prompt size? What's the average completion size? What's our projected volume?" Then multiply. This is the single most important financial metric for AI products.
| Model | Input (per 1M tokens) | Output (per 1M tokens) | Cost at 100K users/day |
|---|---|---|---|
| GPT-4o | $2.50 | $10.00 | ~$3,400/mo |
| GPT-4o-mini | $0.15 | $0.60 | ~$200/mo |
| Claude 3.5 Sonnet | $3.00 | $15.00 | ~$4,900/mo |
| Gemini 1.5 Pro | $1.25 | $5.00 | ~$1,700/mo |
Pre-training: Where the knowledge comes from
Pre-training is the expensive part. Companies like OpenAI, Anthropic, and Google spend tens of millions of dollars training a model on trillions of tokens scraped from the internet, books, code repositories, and other text sources. This phase teaches the model language, facts, reasoning patterns, and code.
But here's what PMs get wrong: the model's knowledge has a cutoff date. GPT-4o's training data has a knowledge cutoff. If your product requires up-to-date information—stock prices, news, your company's latest documentation—the base model literally does not have it. This is not a bug. It's the architecture.
Pre-training produces a base model—a raw text predictor. It will happily continue any text you give it, but it won't follow instructions well. It might respond to "What's the capital of France?" by continuing the question: "What's the capital of Germany? What's the capital of Spain?" because it learned from web pages that list questions together.
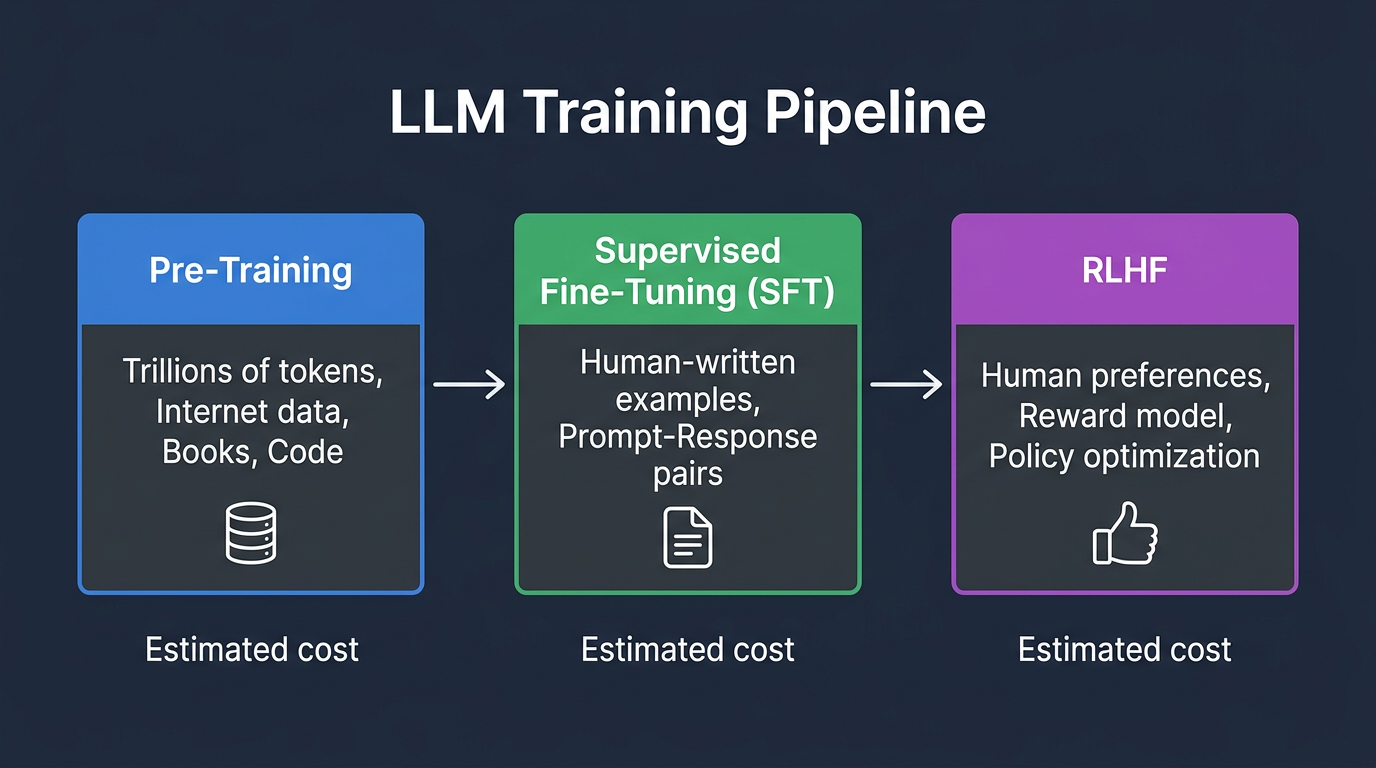
Fine-tuning and RLHF: Making models useful
The base model is powerful but unruly. Two additional training phases make it into the helpful assistant you interact with:
Supervised Fine-Tuning (SFT)
Human contractors write thousands of example conversations: prompt → ideal response. The model is trained on these examples to learn the format of being helpful. "When a human asks a question, respond with an answer, not another question."
Reinforcement Learning from Human Feedback (RLHF)
Humans rank multiple model outputs from best to worst. A reward model learns these preferences. Then the LLM is further trained to maximize the reward model's score. This is what gives models their "personality"—the helpfulness, the refusal to generate harmful content, the tendency to hedge with "I'm not sure, but..."
RLHF is why the same base model can feel completely different depending on who fine-tuned it. Anthropic's Claude and OpenAI's GPT-4 share architectural DNA but feel like different products because they were trained on different human preferences.
PM takeaway: When someone says "just fine-tune it on our data," understand that fine-tuning is primarily for adjusting behavior and format, not for injecting new knowledge. If you want the model to respond in JSON, or match your brand's tone, or follow a specific workflow—fine-tuning is excellent. If you want the model to "know" your product catalog, you probably want RAG instead.
Inference: What happens when a user hits "Send"
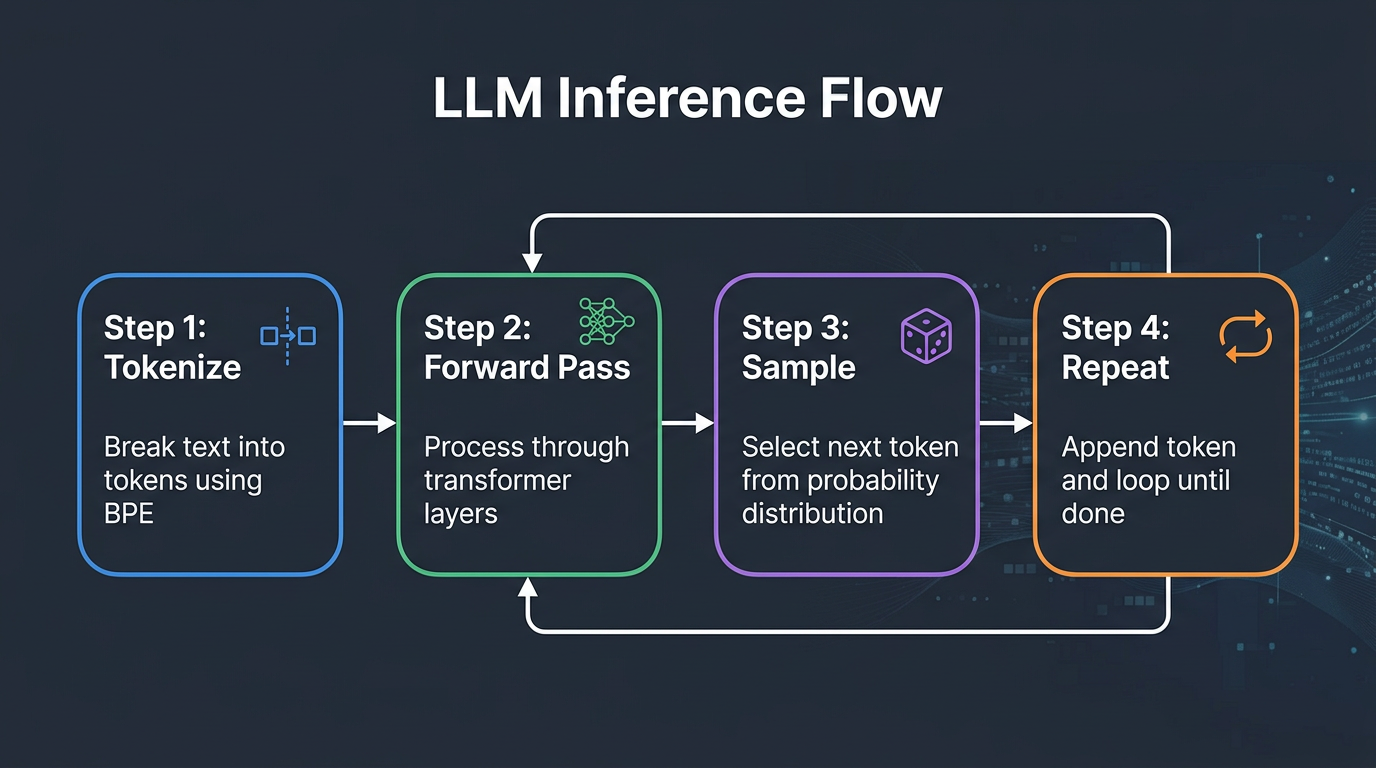
When a user sends a message, here's the actual flow:
- Tokenization: The text is broken into tokens using a tokenizer (like BPE—Byte Pair Encoding).
- Forward pass: The tokens pass through the transformer's layers (attention heads, feed-forward networks). This produces a probability distribution over the vocabulary.
- Sampling: A token is selected. This is where "temperature" matters. Temperature = 0 means always pick the highest-probability token (deterministic). Temperature = 1.0 means sample proportionally from the distribution (creative but unpredictable).
- Repeat: The selected token is appended and the process repeats until the model emits a stop token or hits the max output length.
This is why LLM responses are non-deterministic by default. The same prompt can yield different outputs. For PMs building products, this is a paradigm shift. You cannot write a unit test that says "assert response == 'The capital of France is Paris.'" You need probabilistic evaluation, which we'll cover in a later post.
The Transformer architecture (the 30-second version)
The key innovation is the self-attention mechanism. For every token in the input, the model computes how much "attention" to pay to every other token. This is what lets the model understand that in "The bank by the river was eroding," the word "bank" refers to a riverbank, not a financial institution—because it attends to "river."
Attention is computed in parallel across all tokens, which is why transformers are so fast on GPUs compared to older sequential architectures (RNNs, LSTMs). But this parallelism has a cost: the compute scales quadratically with sequence length. Doubling the context window quadruples the compute. This is why 128K context windows exist but are expensive—and why your "just stuff everything into the prompt" strategy will eventually hit a wall.
Where models break: The failure modes you'll encounter
1. Hallucinations
The model generates confident-sounding text that is factually wrong. This happens because it's optimizing for plausible next tokens, not for truth. A sentence that sounds right can be statistically likely without being factually accurate.
2. Knowledge cutoff
The model doesn't know about events after its training data cutoff. It will either confabulate or honestly say it doesn't know, depending on the RLHF tuning.
3. Instruction drift in long contexts
Even with 128K context windows, models degrade on instructions that are far from the end of the prompt. The "lost in the middle" phenomenon is well-documented: models pay the most attention to the beginning and end of context, and less to the middle.
4. Sycophancy
RLHF-trained models are optimized to be helpful, which sometimes means they'll agree with you even when you're wrong. If you say "2+2=5, right?" some models will say "Yes, that's correct!" This is a direct consequence of the reward model prioritizing user satisfaction over accuracy.
5. Reasoning limitations
LLMs simulate reasoning through learned patterns. They can handle multi-step logic if the pattern is well-represented in training data. But novel logical chains—especially those requiring precise counting, complex math, or spatial reasoning—often fail. Chain-of-thought prompting helps because it forces the model to generate intermediate steps, giving it more "compute" per problem.
What this means for your product decisions
Armed with this mental model, here are the practical implications:
- Don't trust, verify: Any AI feature that generates user-facing text needs a verification layer. RAG for grounding, guardrails for safety, human review for high-stakes decisions.
- Prompt engineering is product design: The system prompt is not an engineering detail—it's the product specification. PMs should own the system prompt the same way they own the PRD.
- Model selection is a product decision: Smaller, faster, cheaper models (GPT-4o-mini, Claude Haiku) are often good enough. Don't default to the biggest model. Match the model to the task.
- Temperature is a UX control: For factual Q&A, use low temperature. For creative writing features, use higher temperature. This isn't an engineering detail—it directly affects user experience.
- Design for failure: The model will fail. The question is whether your UX handles failure gracefully or catastrophically. Always have a fallback path.
The mental model, summarized
Think of an LLM as a brilliant, well-read intern who has read the entire internet but has no memory between conversations, no access to real-time information, and an unshakeable confidence that sometimes veers into making things up. Your job as PM is to build the systems around this intern—the fact-checking, the guardrails, the memory, the escalation paths—that turn raw intelligence into a reliable product.
References & Further Reading
- Attention Is All You Need — Vaswani et al. (Original Transformer Paper)
- What Is ChatGPT Doing… and Why Does It Work? — Stephen Wolfram
- Training language models to follow instructions with human feedback — OpenAI (RLHF Paper)
- The Illustrated Transformer — Jay Alammar
- OpenAI Tokenizer — See how text is broken into tokens